 accesses since August 5, 2002
accesses since August 5, 2002  copyright notice
accesses since August 5, 2002
copyright notice
accesses since August 5, 2002 We present one approach toward information customization that we've found useful in a fairly wide variety of applications over the past fifteen years. A brief history of the motivation of our work is followed by a description of the overall design architecture and the interface considerations. Operational characteristics are demonstrated by reference to several operational prototypes. Although no fewer that four distinct prototypes oriented toward very distinct problem domains have been deployed, our work should continue to be considered a work-in-progress. We conclude with a brief statement of the current status of our work.
Introduction:
Our archetype began to take form in the late 1980's out of a need for more efficient and effective methods of recovering relevant digital images from large image repositories. The received view of image retrieval at that time time was the augmentation of a relational database of descriptions and indices with pointers to individual or clusters of image files. Our goal was to eliminate the need for the "intermediate," meta-level databases, and develop a technology that would relate, in real time, a purely graphical query to all of the images in a repository that matched.
Unlike such prevailing technologies at the time as scene analysis, pattern recognition, image processing, image understanding, and image databases, our approach toward information customization was predicated on the assumption that the customizing software would have to be client-resident, interactive, and involve real-time processing. We'll return to this vision shortly when we provide a formal definition of our information customization archetype.
The following continuum places our early work in perspective:
Highest-level (picture) processing
The critical point for us was the region between edge and boundary detection and image recognition, because we were interested in retrieving stored images based upon entirely graphical queries. This region is especially sensitive in this regard, because the operational domain changes from pixilated data to recognizable objects or components thereof. Figure 1 illustrates this point. Our software produced this scalable outline of 500 straight line segments and 50 Bezier curves from a digitized color image of the Mona Lisa. However, moving from the recognizing the collection of line segments at the bottom-center of the outline from the recognition of two clasped hands is a non-trivial undertaking. In any case, our first foray into a client-side information customization tool that recognized Euclidian objects in images was operational by late 1989. This program took graphical input from a digitizing tablet and returned all images that had image components that matched the input. In this way, if the user drew an equilateral triangle occluding a circle on the digitizing tablet, the software would "peruse" all of the graphics files in the repository, and list the filenames with contents including equilateral triangles occluding a circle (in any context). For the inquisitive, additional detail may be found in reference [1].
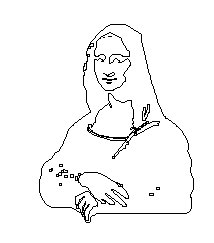
A First Pass at Customizing Graphical Information
The Archetype Defined
Information customization in our view should capture the potential of simultaneously reducing the complexity of data while placing it in a useful context of related queries, images with common object components, document clusters sharing common themes, and so forth. In our view, the following are considered necessary conditions for our information customization archetype:
These conditions are largely self-descriptive, elaboration will follow from the discussion of the prototypes, below. All of our prototypes have remained faithful to these tenets.
Concurrent with our earlier work in image analysis, we began to extend our archetype to textual documents. This placed considerable complexity on the development of the programs, because our objectives were in some cases orthogonal to the standards of the day. To illustrate, since 1990 the World Wide Web has been built entirely upon prescriptive, author-defined hyperlinks. However, for our vision to be realized, the internal document hyperlinks had to be definable by both the information provider and information consumer. This meant that our prototypes had to handle one-half of the hyperlink management (the half directly relevant to the interests of the information consumer) internally, and actually augment the capabilities of existing Web browsers. As an anecdotal datapoint, we first achieved this by developing stand-alone information customization DOS tools that worked with anonymous ftp (circa 1990), later DOS "helper apps" spawned by the Web browser's launchpad (circa 1992), and finally Windows "plug ins" for Netscape and Internet Explorer (1995 on). Aspects of this development were reported in a series of technical reports [e.g., 2-4], with high-level overviews appearing in the professional literature [5-8].
Architectural Properties of our Information Customization Archetype
As mentioned above, several varieties of prototypes have been developed that were faithful to our vision of information customization from 1989 to the present. A small, inter-related set of architectural considerations were shared by most of the prototypes. A few of them are listed below.
By way of comparison, the following table compares information customization with traditional information retrieval and filtering techniques.
TABLE 1
A Comparison of Information Customization with Information Retrieval and Filtering
| retrieval/filtering | customizing | |
| orientation: | acquisition | transformation |
| input: | set of documents | single document or semantically coherent document cluster |
| output: | subset of documents | document extract and meta-level information |
| transformation: | no | yes |
| doc. structure: | linear or non-linear | linear or non-linear |
| nonlinearity: | prescriptive | presecriptive and non-prescriptive |
| links: | persistent | dynamic (on the fly) |
| scalability: | limited | irrelevant |
| interface: | non-interactive | interactive |
| examples: | keyword vectoring semantic indexing | document extraction |
In the interest of expository parsimony, a complete explanation of these characteristics will be avoided in favor of an overview of two of the prototypes since the details of these characteristics appear in the references.
Vintage Prototypes
Figure 2 is a screen shot of the second operational prototype developed in 1992-3. It is worth remembering that this was before Microsoft Windows had become an industry standard on the desktop!

IC Prototype #3 - "Schemer (circa 1992)"
The basic functionality of the prototype, called "Schemer" because it allowed the user to define multiple viewing schemes in the database sense for document clusters, can be inferred from the interface. A few salient characteristics deserve elaboration.
First, by this time we had developed a "text algebra" that drove the creation of the document extract (see bar at bottom of screen). The 20 columns in the main "window" correspond to the keywords listed above. The numbers after the keywords denote a relevance "weighting." Several algorithms were used for this purpose over the years, including comparison against standard word frequency calculations (e.g., the Brown Corpus). These "weighting" measures could be toggled off-and-on at will. The color of the keyword relevance value signified the algorithm used in determining its relevance.
Armed with the text algebra, and keywords of interest (highlighted vertical bars), one could produce a variety of document extracts with function keys. One such extract appears in Figure 3. The creation of extracts is done interactively and in real-time by means of the text algebra controls. Prototype 3 was designed to run as an independent program or, in later releases, run as a helper app launched by a Web browser. Standard text formats as well as HTML were supported as input.
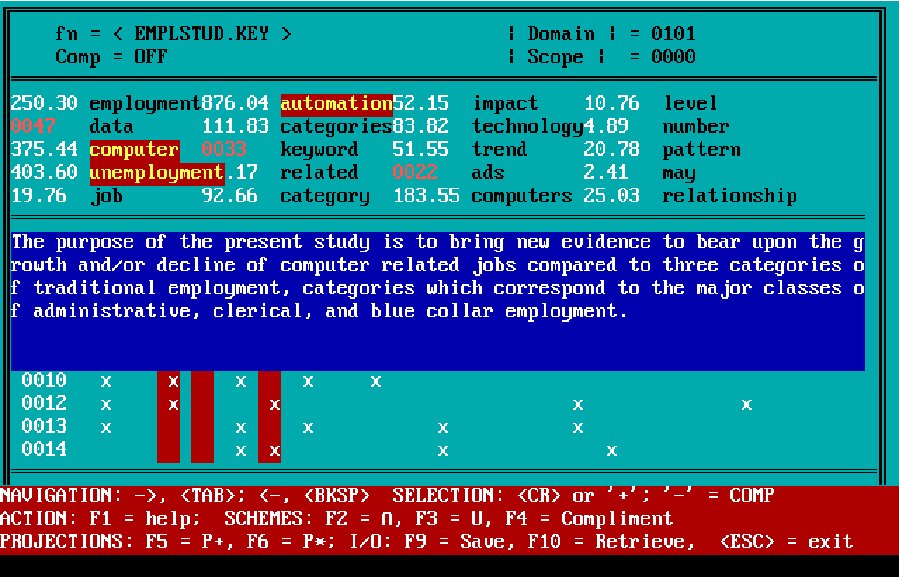
Interactive, Real-Time Document Extraction Capabilities of
IC Prototype #3
Figure 4 shows how the interface and functionality had evolved by the mid-1990's. By then, Windows was the dominant operating system on the desktop, and plug-ins had displaced helper apps as the de facto standard browser launchpad. One observes that the text algebra had been extended to include a variety of fully-automated features producing document "kernels," "meta-level kernels," and so forth.
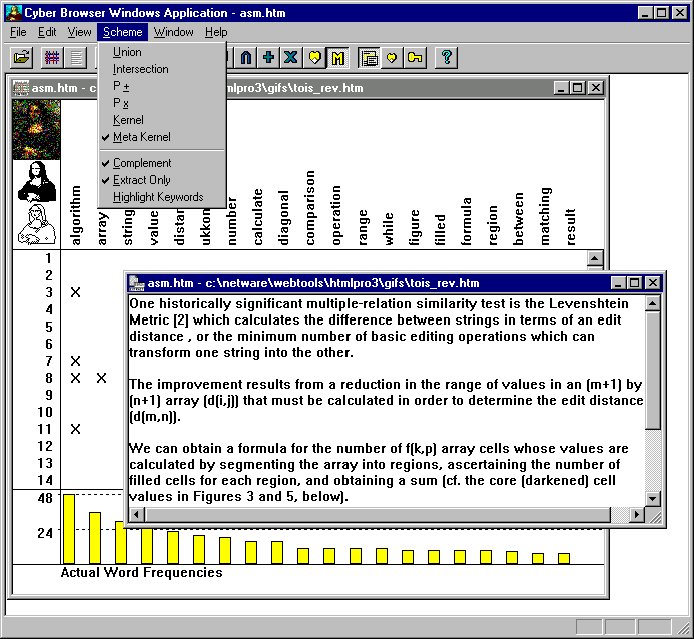
Information Customization Client with Modern Windows Interface
Future Work
Our information customization archetype is but one of many possibilities. What makes ours distinctive is a combination of factors ranging from the distinctive approach to fundamental principles listed above, to the details of the text algebra that we defined to control the extraction process. The non-proprietary details of functional characteristics of our prototypes appear in the literature, below, and is omitted here in the interest of brevity.
It should be mentioned that our interest in customization of non-textual, digital media waned by 1991 because the technology and underlying research was not amenable to incremental advances. While we created a customizing environment for the recognition of geometrical objects in specially-created graphics test files, the extension to real-life images involved orders of magnitude more complexity and required funding levels beyond our capability to attract. The customization of text-based documents, on the other hand, was amenable to both incremental advances and modularization (e.g., adding another extraction algorithm, extending the text algebra by a few features, etc.). So it is within this environment that we have exclusively focused our attention for the past decade.
Much of our current development effort involves extending our information customization archetype for distributed, peer-to-peer applications in order to sustain dynamic information customization collaboratories between communities of users. Some insight may be gained on our objectives in the final two references [9,10]. Our long-term goal is to provide a networked framework for collaborative information customization where clusters of participants can share varying degrees of customized results and learn from each other's experience. For example, a consistently effective user in one location may have a cluster of documents and document extracts to which others would like access. Their results, in turn, would be made available to the user that initiated the process. We remain convinced that the appropriate network model for this collaboration is peer-to-peer.
References: