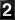
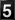
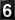
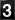
 accesses since June 15, 1996
accesses since June 15, 1996 copyright notice
accesses since June 15, 1996
copyright notice
accesses since June 15, 1996
As I give talks on the World Wide Web, and demonstrate the work that we do, I am frequently asked about our CGI programming techniques. "How did you do that?" , "How can we make a Web Widget?", and so forth.
In many cases, these questions come from managers who just don't know what direction to take with the Web (see also my column "Does Your Business Need the Web" a few issues back). Managers sometimes find themselves torn between the desire to get their organization up to Web-speed on the one hand and the risk of wasting time and money on distractions which won't improve their bottom line on the other. Analysis paralysis is not uncommon.
Here is my humble offering to my manager and end-user friends who want to know just enough about Web technology to have a basic understanding of how the Web works to articulate their requests to technicians. Since I've already dealt with the basics of HTML document preparation in earlier installments, we'll begin with the basics of CGI - the Common Gateway Interface.
Those of you who follow Cybernautica will recall that I define the Web as a pair of killer protocols, HTML and HTTP. The former defines the structure and appearance of all Web documents while the latter provides the handshaking necessary for the client and server to communicate with one another. In it's simplest form, however, this communication is pretty one-sided: the client requests something from the server, the server acknowledges the request and complies, whereupon the client requests something else, and so forth. While this arrangement works well for locating and viewing cybermedia (CYBERspace multiMEDIA), it's pretty primitive. The interactivity between the user, the client and the server is pretty much restricted to downloads and links.
The need for additional interactivity became obvious early on in the evolution of the Web. The second iteration of Web specifications, version 1.0 of the Web standard promulgated by the Internet Engineering Task Force, was built around the CGI extension. This was called the so-called "forms" extension. The FORM tag is an HTML extension which accommodates CGI programming.
We will illustrate CGI capability with a simple example. Suppose that we decide to add our office business hours along with the local time to our business homepage so that people will know if we're currently open for business. That's all, we just want to add the time and business hours.
Our business hours can be hard-coded in the HTML document since they don't change very often. Providing the local time, on the other hand, would be a major hassle under HTML 1.0 specifications. In fact, it would require preparing as many different HTML documents as there are minutes in the day. The server would then determine the local time, translate that into a filename, and report the corresponding document. Just imagine a directory of almost identical files <homepage_12-00am.html>, <homepage_12-01am.html>,..., <homepage_11-59pm.html> - 1,440 HTML documents in all - just so the user could see the current time on our server.
The problem was that prior to HTML 2.0 (circa 1994), the HTML documents were static - there was no way for the server to modify them on-the-fly. The server's internal clock kept track of the time, but there was no mechanism by means of which the server could insert that into the static HTML document. A serious deficiency, indeed.
HTML 2.0 fixed all that, and a lot more, with the Common Gateway Interface - CGI for short. It is the mechanism by means of which the Web comes alive with interactivity. Interactive forms, continuously updated access counters, visitor's logs, sensitized imagery, and search engines all use the CGI.
From the user's perspective, CGI may be thought of as a collection of programs which run on a server. These programs may be written in any language which is capable of interpreting the standard input, output and environmental variables which are used to communicate between clients and servers. For ease of use, it is helpful if they are well-suited for string manipulation and interface with a wide variety of available libraries and utilities, particularly in the database and multimedia areas.
Such CGI programs fall into three basic categories:
Any of these environments will work for simple CGI programming. Perl, however, is the clear choice of the professionals for robust CGI programming. The shell scripts, especially C-shell, are considered too impoverished for sophisticated applications.
While CGI programs may reside in any subdirectory which a system administrator allows for CGI binary files (hence the nickname "cgi-bin"), there are certain generally accepted conventions followed. For example, Perl script is usually run from #!/usr/local/bin/perl subdirectories while Bourne shell programs run from #!/bin/sh. This assumes that your server is set up to support the #! syntax for specifying translators. If this is not the case, you will need a work-around from your system administrator. CGI-bin rules-of-the-road are fairly standard. Check your system administrator for details.
The invocation of CGI scripts is accomplished from within an HTML document. Let's use our local time problem as an example. Under HTML Version 2.0 we could include in an HTML document an instruction for the server to run a program which will report the current time at the exact place in the HTML document where the directive occurred. The HTML document would become dynamic. Only one document would be created, with a small window for the current time left in it, and the time would be updated only when it was requested. A much more satisfactory way of reporting the local time than having 1,440 tokens of the same homepage.
The current time example is really a special case of CGI
programming. The more general case would be where the client
would request a CGI executable file as a URL (Uniform Resource
Locator). To illustrate, suppose that we requested the
Perlprogram, <howdy.pl>, in the URL
http://www.my_company.com/howdy.pl. In this case, the message
from the client to the server would specify (a) the protocol
which is to be used to exchange information (e.g., HTTP/1.0), (b)
the data formats which the client can render (e.g., text/html,
image/jpeg), and (c) the program,
In broad strokes, this is what CGI is all about. Providing additional interactivity between user, client and server with the goal of creating dynamic HTML documents.
We'll conclude with a straightforward example. Some of the detail will be left out for the sake of brevity.
Figure 1 illustrates a generic, vanilla, nuts-and-bolts example of CGI programming. This is the homepage of our World Wide Web Test Pattern at http://www.uark.edu/~wrg/ (see PC AI, Nov/Dec, 1995). The Test Pattern enables end-users and developers to easily determine the level of HTML compliance which a Web browser can handle. Some basic HTML features are present: textured background, stationary image, sensitized icons and hyperlink anchors. However, the "Visitor's Bureau" at the bottom represents the dynamic, CGI part of the document.
The Visitor's Bureau reports information which is derived from the packets exchanged between the client and server over the Internet. In this case, visitor number 12,194 (me) accessed the Test Pattern with a Netscape Mozilla browser (version 3.0b3Gold, to be exact) while it was running on a PC whose operating system was Windows NT. This access was made on Thursday, the 20th of June, 1996 at 4:13 central time. All of this information was inserted into that space of the HTML document before it was sent to the client for display.
A hint that something beyond basic HTML tagging is going on in the presentation of this document may be found in the document source (one of the options under "view" on your browser's menu) in Figure 2. A glance at the bottom of the document source will reveal the text of the information together with some references for GIF graphics files <1.gif>, <2.gif>, etc. The GIF files are actually the individual images of the numerals which make up the odometer. Since the text and counter graphic apply to my access, there has to be some program(s) in the background which produces this information interactively and in real time.
This fact can be easily detected if one copies the actual HTML source document (as distinguished from the source HTML as "viewed" within the browser). One can do this by using an FTP (file transfer protocol) client to download the file to your computer. Figure 3 shows this version of the document.
Figure 3 is the unadulterated document source prior to any modification by a CGI program. The mystery starts to unravel when we look at this version of the source. Directives like <!--#exec cmd="../Count.pl"--> betray the fact that a program is being executed at that point in the document. This particular program, Count.pl, is a Perl program - hence the file extent .pl. We assume, correctly, that <Count.pl> has something to do with the counter.
What is happening is this. The document is actually being parsed by the server. The parts that are pure HTML are skipped and reported back to the client for rendering. The parts that are directives or "exec" commands are recognized as such and executed. The output of these programs is the "magical" input which appeared in the HTML source in Figure 2, and in turn in the HTML document in Figure 1.
If you're confused, just remember that the version of an HTML document which is rendered by your Web client is the document source AFTER any CGI programs have operated on it. The HTML source which you FTP is the "actual" document source with the CGI program directives in it.
This is the first of several columns which I'll write on the technical side of Web programming. Within a few months we'll be talking CGI with the pros.
Next Up: CGI Environment Variables. Stay tuned!